
今日は大阪の難波にある自習スペースでテンションの上がる洋楽を聞きながらブログを書いてます。今回は教育委員会のブログです。今回のネタでAIや機械学習の話は一旦終わりにしようかなと思っています。次回からは、もっと身近な題材をテーマにしてみたいと思います。
今日のお題は「時代とともに変化するシステムへの要求」についてです。なんか小難しいお題ですが、ざっくりと書いてみます(でも今回も長いです)
■要求とは?
システムを作る立場から考えた「要求」とは、仕様に該当する部分です。
一般的なシステムやアプリケーションの設計ではお客様からヒアリングした内容の「要件定義」や「外部設計」、「詳細設計」に該当します。自社開発のシステムであれば、顧客に該当する部分も設計者が担当します。
■要求は変わらない?
では、システムを設計した時点から要求は不変なものなのでしょうか?
おそらく答えは「NO」です。
システムを構築した後も、仕様変更や不具合対応でシステムの要求は変化します。また、不特定多数をターゲットにしているサービスやシステムは、顧客のニーズや時代の流れによっても機能を拡充していかないと時代の波に取り残されてしまいます。
時系列で言えばこんな感じになります。

設計する側から言えばたまったものではありませんね。
■要求におけるアプローチ
このような問題はコンピュータシステムが登場してから、ずっと続いてきた問題です。プログラム言語作成者や、システム設計者はこの問題に対して様々なアプローチを考えてきました。今日はそれを概念レベルでざっくり解説してみます。
1.オブジェクト指向による制約プログラム
これは、インターフェースや抽象クラスによるポリモーフィズムを利用して、要求に対して変化が発生する可能性のある部分を制約によって局所化する手法です。
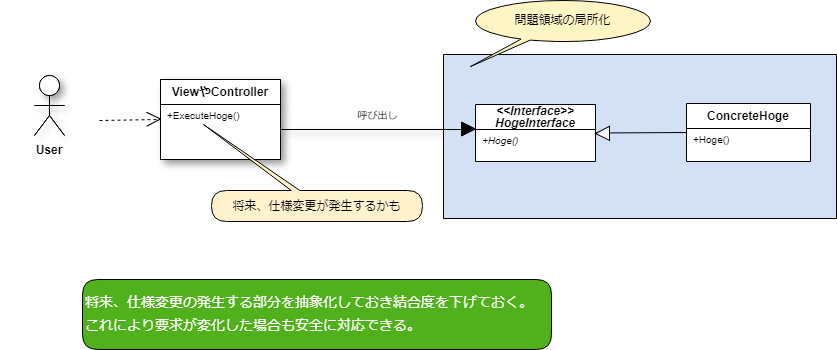
よく使われる制約のパターとして「GoFのデザインパターン」があります。振る舞いを動的に変化させて仕様追加や変更を容易にするStrategyやStateパターン、要求の詳細を隠蔽すして変化に強くするFacadeやBridgeパターンなど、パターンの生まれた背景には「要求の変化」というものへの対応が考慮されているものが多く提案されています。
2.不具合修正の保険「フック」
一度リリースしたシステムを更新するには大きなリスクが伴います。特に、OSや市販パッケージのような不特定多数に販売される製品には、このリスクが大きくなります。OSのような巨大なシステムをコンパイルして配布となると、ネットワークトラフィックやリソースも馬鹿になりません。ほんの小さなバグだけど、深刻な対応が必要な不具合が見つかった場合、どのようにすれば良いでしょうか?
「フック」とは「ひっかける」という意味があり、あらかじめ変化が発生しそうな部分にフックの機能を組み込んでおきます。リリース後に問題が発生した場合は、このフックの機能に不具合改修のコードを入れて差分をリリースします。わかりやすく言うと「処理を迂回できるポイントを用意しておくことです」
携帯電話のOS周りの開発をしていた時は、いくつもの会社がプロジェクト単位で参画し、開発が行われていました。リリース(発売時期)は絶対で、これを守れないプロジェクトチームは毎回のように炎上していました(当時、携帯電話の開発はブラックな現場の代表格でした。私の管理していた3キャリアのチームはメンバーの年齢層も若く、求めるスキルやルールは厳しかったですが、ほぼ毎日定時で終わってリリース時期もきっちり守れていました)
このような大規模なシステムをコンパイルする場合は、全てをコンパイルする必要があるため、申請からコンパイルまで数日かかりました。一度コンパイルをしたモジュールを再コンパイル申請する場合は、様々なテストを行い、必要な手続きを行い、それに全てパスする必要がありました。
その手続きを省略するために、あらかじめフックできる関数ポインタを引数の予約として設定して申請しておき、軽微な修正や変更が発生した場合はその引数にアドレスを渡して対応していました。言語はCでしたが、将来発生するかもしれない仕様変更に対し、少ない工数で対応を可能にする「予防策」を講じることにより、影響範囲を明確化し、テスト工数も含めた工数を削減していました。
この手法は、OSの一部でも利用されていますが、フック可能なAPIは悪意のある人の恰好のターゲットになる可能性があるので実装側は十分なスキルと対策が必要になります。
3.作成後の要求や変化に対応する「コールバック」
アプリケーションを作成したあとに要求が決まることがあります。販売したあとに「要求」が決まるので、作成段階ではこの「要求」を知ることはできません。そこで登場したのが「コールバック」の概念です。
コールバックの手法は、アントニー・ホーアが開発したC言語の「qsort」のアルゴリズムが有名です。アルゴリズムの部分は不変であるが、並び順を決定するアルゴリズムの部分は利用側(qsortを使う開発者)に委ねました。これにより、高速なソートアルゴリズムを開発する場合でも、開発者は並び順を考えるだけですむようになりました。
また、VBや.NETアプリケーションに代表されるような「イベント駆動型」の言語も「イベント」や「delegate」のコールバックを利用して開発を行います。
Officeアプリケーションなどには、ユーザが独自にカスタマイズ可能なアドオンの機能が用意されています。これも本来アプリケーションにない機能(要求)をユーザが独自に拡張できる仕組みです。
アドオンにもインターフェースやコールバックの技術が使用されています。
またフックとコールバックの進化系として、概念をさらに抽象的に解決するための仕組みがあります。これは「依存性の注入(DI:Dependency Injection)」と言いマーティン・ファウラーが提唱しました。関数ポインタではなく、外部の設定ファイルなどからデータを取り出し、本来の処理を行う前に前処理や後処理をフックして、本来の処理には関係のない「依存性に該当する部分」を外部から注入する仕組みです。
4.データによる「要求」の変化
ちょっとだけ視点を変えてみましょう。PCのデスクトップに「Excel」のドキュメントがあります。ダブルクリックしたらどうなるでしょうか?Excelが起動して、ダブルクリックしたドキュメントが開かれますよね?
OSが設計される段階では、利用者がダブルクリックする位置も、その位置にどのドキュメントが保存されているのか、そのPCにどのようなアプリケーションがインストールされているかもわかりません。OSはダブルクリックされた位置を判断し、ファイルが存在する場合は拡張子に対応したアプリケーションの引数に、そのファイルのフルパスを渡します。
このような「拡張子」というデータに対してどのアプリケーションを起動するのかという「要求」を動的に切り替えています。
5.AIと要求
では、今流行りのAIにおける要求とはなんでしょうか?
ロボット型の汎用的なAIではユーザからの要求に即座に応答する必要があります。
ユーザは様々な質問をしてきますし、その答えは必ずしも決まっているわけではありません。
AIは学習により「データ」と「アルゴリズム」を切り替えながら「答え」を導き出していきます。
与えられた「要求」に対し、適切な答えを出せるか「認識」を行い、答えまでに到達する「評価」を繰り返し、最終的なアウトプットを決定します。

ここで注意しなければいけないのは、その答えが「正解」ではない可能性があることです。与えられた問題に対して事実上実行可能(到達可能)な最適解、もしくはセミアクティブ解のような解になる可能性もあります。AIも常に学習を行い、自分のアルゴリズムを変化させていきます。翌日同じ質問をしたら答えが変わっているかもしれません。
時代の速さと要求へのレスポンス
今回は、人間の「要求」にスポットをあてて、その要求に答える手法や考え方をざっくり説明してみました。時代の変化のスピードと人間の要求にリアルタイムで対応するには今後もAIの技術は必要不可欠になります。
開発環境にもAIが搭載される時代です。AIは定型の業務や共通項を見つけることは得意なので、よくあるシステムはAIが作る時代が来るかもしれません。AIは24時間稼働で、コーディングの速さもおそらく私より速いでしょう。AIを使って開発をすると今までより遥かに高い生産性が得られるはずです。
最初はVisualStudioのインテリセンスのように「知見」から得られた「ヒント」をあなたにアドバイスしてくれるでしょう。
今から15年くらい前、.NET Framework1.0が登場してまず私が最初に行ったのはRefrectionを使用したソースの自動生成でした。以前から使っていたSQL Serverからテーブル情報やリレーション情報を取得して、ファイル出力でソースの自動生成を行うツールを、Refrectionを使用してMethodInfoやMemberInfoを動的に作成するように再設計しました。
DBの設計を行ったら必要なエンティティやデータアクセスのプログラムは全てRefrectionで自動生成、お決まりのDB処理やエンティティ生成は全てプログラムに作らせました。 このやり方でよかった点は、DB設計やUI設計、ビジネスロジックの設計に注力できること、定型の面倒なコードやミスが入り込みやすいCRUD部分は一切作成しないこと、そして何より一番恩恵のあったことは「バグ」がないということでした。
取り扱い商品数万件の業務システムでも短期間に1人で十分作成できました。そのシステムは今も稼働していますが、法令などによる外部的な要因や、お客様の要求による帳票レイアウト等の変更はありましたが、不具合は1件もありませんでした。
上記の仕組みは特定のDBをターゲットにしていたため、汎用的ではなかった点と、DB構造とエンティティが1:Nになる複雑なリレーションは手動で作成する必要があるという点、テーブル名や列名が自動で作成されるため大規模システムのような独自のテーブル設計方針やコーディングルールがある場合はマッピングしにくい点でした。
このあとDIコンテナのSeaserプロジェクトに参加しましたが、私と同じような考えをする人が多くいて様々な観点からプロジェクトは進化していきました。現在はこの問題はDIコンテナなどのフレームワークが解決していますが、これからはAIによってさらにコーディング不要な時代が到来すると思います。
さらに時代が進化してくると、AIはあなたの作ったプログラムに対して「評価」をしてくるでしょう。チェスのDeepBlueのように、膨大なパターンに対して評価付けすることはAIにとっては得意な分野です。コードの自動生成やリファクタリングはアイデアも技術も成熟してきている分野です。問題個所を見つけてどんどん素晴らしいコードをあなたに提案してくるでしょう。AIとコードの自動生成が融合するとAIは様々なプログラムを作成して自分のコードに評価を付けて品質を上げていくでしょう。そして最後には完成したプログラムだけをあなたに見せてくる時代がくるかもしれません。世界中の優秀なエンジニアから得られた「知見」によって生成されたプログラムをあなたは正しく理解できるでしょうか?
これからの技術者に求められること
チームとしてプロジェクトを進めるにはメンバーのスキルや健康状態、モチベーションの管理など開発以外の要因によって生産性が大きく左右されます。これらによって引き起こされる納期遅れや現場の炎上、品質の悪いソースコードなどはAIによってなくなるかもしれません。
色々なチームでプロジェクトを率いてきましたが、生産性と品質は「ヒト」によって大きく左右されます。平均的な技術者が数十名いるプロジェクトより、優秀な技術者が数名のプロジェクトの方が遥かに高い生産性と品質のシステムができるという話は今では周知の事実です。日本のシステム業界は、まだ大手が人月商売をしているため、世界から見ると遅れた開発現場が大半を占めていますが、これからはお客様の視点もどんどん変わってきます。
優秀な技術者はAIという武器を手に入れ、さらに生産性を上げていきます。チームはさらにコンパクトになり、数名のシステムアーキテクチャとAIでプロジェクトが完成します。
AIがコーディングする時代になっても技術者として生き残れるかどうか、AIの得意・不得意を理解してAIを使いこなせるか。それがこれからの技術者に求められてくるスキルになると思います。AIが間違った答えを採用しないような高度な抽象化概念を教育できるスキル、コーディングやシステム独自のイディオムを適切にAIに学習させることのできるAIやアルゴリズムのスキル、AIにシステム品質を学習させるための総合的な知識。これらが全て求められる時代に突入しています。
AIに使われる人間より、使う人間でありたいと思います。
